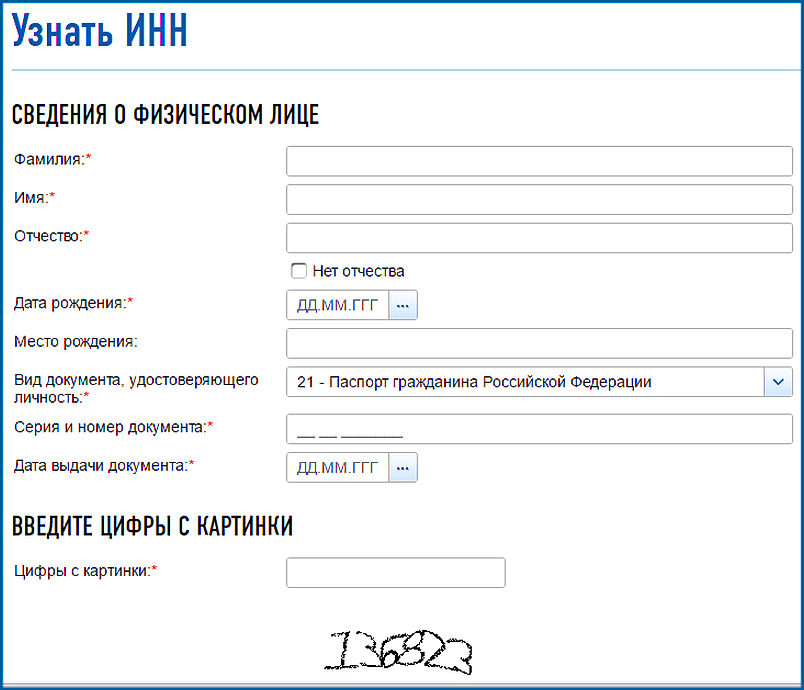
Узнать ИНН
Информация об ИНН не найдена. Рекомендуем проверить правильность введённых данных и повторить попытку поиска.
По указанным Вами сведениям в Едином государственном реестре налогоплательщиков (ЕГРН) не найден ИНН физического лица, присвоенный при постановке на учет в налоговом органе.
Внимание! Если в настоящее время физическое лицо имеет новый документ, удостоверяющий личность, рекомендуется повторно заполнить форму запроса, указав при этом реквизиты предыдущего документа, удостоверяющего личность физического лица.
Если физическое лицо имеет документ, подтверждающий постановку на учет,
для уточнения имеющихся в налоговых органах в отношении такого
физического лица сведений рекомендуется обратиться указанному
физическому лицу в налоговый орган по месту жительства (при себе
необходимо иметь документ, удостоверяющий личность, и документ,
подтверждающий постановку на учет – свидетельство или уведомление), либо
отправить в инспекцию ФНС России заявление на уточнение персональных
данных через сервис Личный кабинет налогоплательщика для физических лиц, либо
воспользоваться сервисом Обратиться в ФНС России.
Если физическое лицо не имеет документа, подтверждающего постановку на учет, такое физическое лицо может для постановки на учет и получения ИНН обратиться в налоговый орган по месту своего жительства (при себе необходимо иметь документ, удостоверяющий личность), либо воспользоваться сервисом Подача заявления физического лица о постановке на учет.
Скрыть подробную информацию
ОКПО по ИНН узнать бесплатно онлайн
Для идентификации и учета организаций и предпринимателей государство создало множество классификаторов. Среди них общероссийский классификатор предприятий и организаций (ОКПО) – самый базовый, на его основании предприятию присваиваются другие коды статистики. Он облегчает государству задачи проведения статистического анализа и управления информацией о субъектах хозяйствования. В статье разберем, что такое код ОКПО, для чего он нужен, где его можно узнать и какую информацию он позволит получить.
Что такое код ОКПО
Чтобы легализовать деятельность, все предприятия должны получить код ОКПО. Он указывает направление деятельности, в котором работает предприятие. Объекты классификации по ОКПО:
- Юридические лица;
- Организации без образования юрлица;
- Индивидуальные предприниматели.
Органы государственной статистики в обязательном порядке присваивают код каждой организации или ИП при регистрации. Это происходит автоматически на основании данных ЕГРИП и ЕГРЮЛ.
Присвоенный код ОКПО, хозяйствующий субъект сохраняет в течение всего периода деятельности. Реорганизация или смена юридического адреса не требует его изменения. Однако при смене вида деятельности, код изменяется. Получить новый можно в органах Росстата, указав причиной смену отрасли. При ликвидации предприятия код удаляется из классификатора и не может быть использован еще 5 лет. Одинаковых кодов ОКПО нет.
Для чего нужен ОКПО
В первую очередь, ОКПО нужен Росстату для проведения статанализа и налаживания информационного обмена.
Код ОКПО не менее важен для организаций и их руководителей. Только после его получения деятельность становится легальной. Без кода нельзя изменить учредительные документы, открыть новый филиал или сменить руководителя. К тому же, код является обязательным реквизитом для множества документов: договоров, соглашений, лицензий, актов.
Код ОКПО не является конфиденциальным. Зная код, можно провести поиск по базам данных и узнать официальную информацию о субъекте. Зная код ОКПО, легче получить доступ к другим реестрам и проверить, добросовестно ли выполняет ваш контрагент свои обязательства перед государством, не открыта ли процедура банкротства в его отношении.
Из чего состоит ОКПО
Классификатор ОКПО состоит из двух частей. Первая предназначена для организаций, вторая — для ИП. Каждая часть состоит из трех блоков:
Блок идентификации содержит код ОКПО. Код ОКПО организаций имеет 8 знаков, ИП — 10 знаков. Первые цифры кода определяют сферу деятельности:
Код ОКПО организаций имеет 8 знаков, ИП — 10 знаков. Первые цифры кода определяют сферу деятельности:
- природные и трудовые ресурсы;
- продукты труда и производственной деятельности;
- субъекты народного хозяйства;
- управление и документация.
Последняя цифра — контрольная, для ее расчета используют методику расчета контрольного числа, установленную правилами стандартизации.
Блок наименования объекта. В этом блоке указывается наименование организации или ИП. Для организаций в коде ОКПО указывают полное или сокращенное наименование организации и, при наличии, ее наименование на английском языке. Для предпринимателей указывают, что субъект является индивидуальным предпринимателем, и фиксируют Ф.И.О.
Блок классификационных признаков содержит коды других классификаторов. В нем находится информация о шести классификаторах: ОКАТО, ОКФС, ОКОГУ, ОКОПФ, ОКВЭД и ОКТМО.
Классификатор существует только в электронном виде и постоянно изменяется. Добавляются новые организации, ликвидируются существующие, меняются виды деятельности.
Добавляются новые организации, ликвидируются существующие, меняются виды деятельности.
Как узнать код ОКПО для организации или ИП
Первоначально код ОКПО выдается Управлением Росстата при регистрации предприятия. Кроме того, узнать код ОКПО можно, заглянув в документацию. Код является обязательным реквизитом во многих документах и нередко бывает указан на печати.
Если код утерян, то можно запросить новую выписку с кодом в Росстате, но это платная услуга. Для этого в Росстат нужно подать запрос и представить свидетельство ОГРН, ИНН, выписку из ЕГРЮЛ/ЕГРИП. В течение 5 дней вам предоставят ответ с кодом.
Чтобы получить информацию о контрагентах, можно обратиться в отделение ФНС по месту жительства. Заполнив заявление, вы сможете получить информацию по ОКПО лично или по почте в течение 5 дней.
Бюрократизация и негибкость государственных структур создают проблемы при обращении: необходимость подавать заявление лично, стоять в очередях, оплатить госпошлины. Есть способ проще — воспользоваться интернетом. Поисковая система поможет выйти на сайт организации. Многие фирмы публикуют код ОКПО на своем сайте среди реквизитов.
Есть способ проще — воспользоваться интернетом. Поисковая система поможет выйти на сайт организации. Многие фирмы публикуют код ОКПО на своем сайте среди реквизитов.
Как узнать ОКПО по ИНН
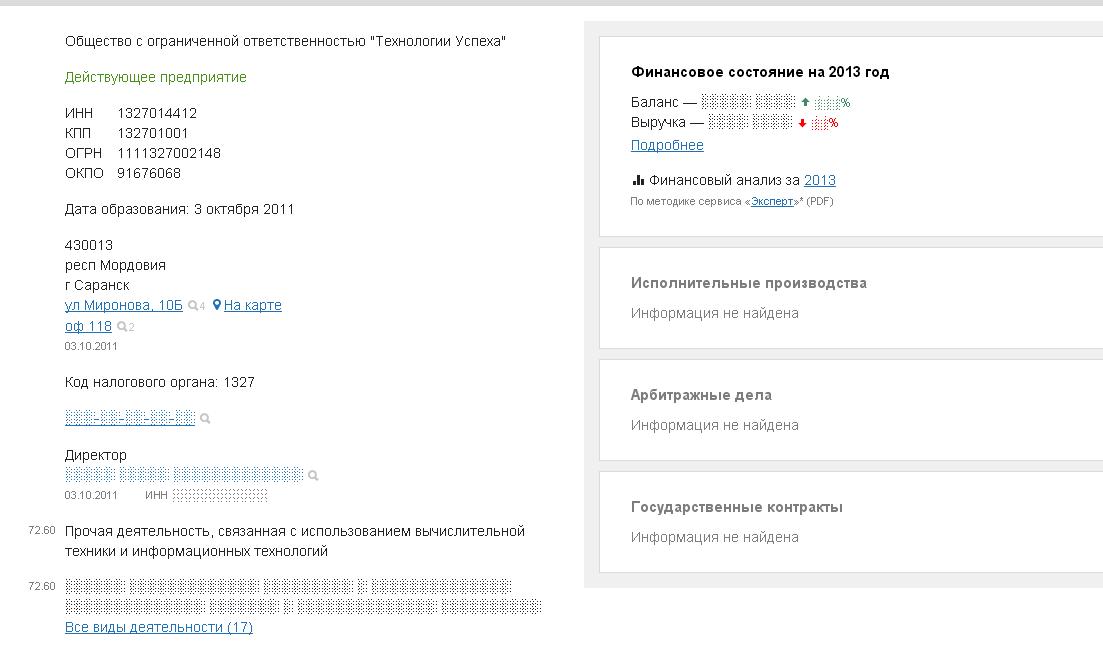
Федеральная налоговая служба разместила на своем сайте онлайн-сервис для проверки контрагентов. Для этого нужно выбрать электронный сервис «Риски бизнеса» и ввести ИНН, ОГРН/ОГРНИП или наименование юрлица или ИП. С помощью сервиса, вы сможете узнать юридический адрес компании, но не код ОКПО. Зная адрес, вы можете обратиться в районную администрацию и запросить код там.
С помощью ресурсов okpo.ru и egrul.com можно за плату оставить заявку на получение кодов статистики или запрашивать выписки из государственных реестров.
Самым быстрым и надежным способом является поиск кода ОКПО на сайте Росстата (http://statreg.gks.ru/). Он позволяет сформировать и распечатать уведомление. Чтобы начать поиск, нужно указать один из реквизитов: ОКПО, ИНН или ОГРН. В результатах поиска отразится организация, и сформируется уведомление.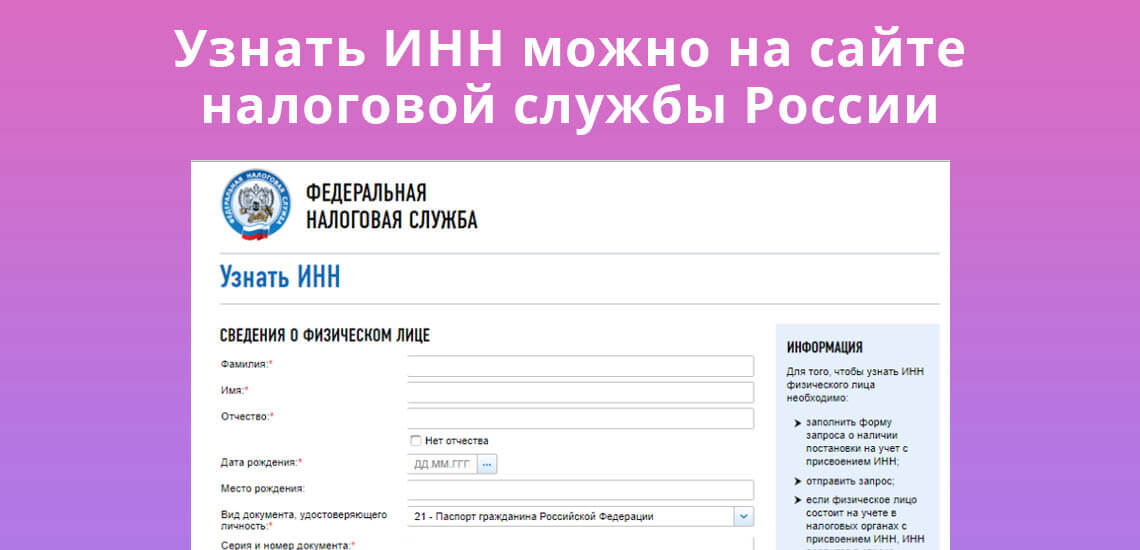
Автор статьи: Елизавета Кобрина
Используйте надежные источники: веб-сервис Контур.Бухгалтерия позволит узнать код ОКПО контрагента за пару минут. Кроме того, первые 14 дней пользования предоставляется возможность работать в сервисе бесплатно. Вы можете вести учет, отправлять отчетность, начислять зарплату и получать консультации наших экспертов.
Лицензия | Генеральная лицензия Банка России на осуществление банковских операций №1481 от 11.08.2015 г. |
Полное наименование | Публичное акционерное общество «Сбербанк России» |
Сокращенное наименование | ПАО Сбербанк |
Юридический адрес | Россия, Москва, 117997, ул. Вавилова, д. 19 |
Почтовый адрес | Москва, 117997, ул. |
Телеграфный адрес | г. Москва, В-312, Россбербанк |
Телефакс | + 7 (495) 957-57-31, + 7 (495) 747-37-31 |
Телетайп | 114569 SBRF RU |
Телекс | 414733 SBRF RU |
Реквизиты ПАО Сбербанк | Кор. счет: 30101810400000000225 в Главном управлении Центрального банка Российской Федерации БИК: 044525225 КПП: 773601001 ИНН: 7707083893 |
ОГРН | 1027700132195 |
Коды | ОКПО 00032537 |
Запись о регистрации кредитной организации – эмитента внесена в ЕГРЮЛ 16. 08.2002 08.2002 | |
SWIFT-код | SABRRUMM |
Код Reuters Dealing | SBRF, SBRR, SBRO |
Сайт | www.sberbank.ru, www.sberbank.com |
Дата внесения в ЕГРЮЛ | 16.08.2002 |
Руководитель | Президент, Председатель Правления ПАО Сбербанк – Греф Герман Оскарович |
Главный бухгалтер | Старший управляющий директор, главный бухгалтер – директор Департамента учета и отчетности Ратинский Михаил Сергеевич |
Заместители главного бухгалтера | Старший управляющий директор, заместитель главного бухгалтера – начальник Управления бухгалтерского учета и отчетности Миненко Алексей Евгеньевич Управляющий директор, заместитель главного бухгалтера — начальник Отдела реализации национальных отраслевых и внутренних стандартов Вялова Вера Анатольевна |
Как проверить организацию или ИП по ИНН/ОГРН.
 Узнать ИНН физического лица по паспорту
Узнать ИНН физического лица по паспортуВ настоящее время с помощью сервиса Федеральной налоговой службы «Риски бизнеса: проверь себя и контрагента» стало возможным проверить сведения о контрагенте (поставщике, подрядчике или покупателе). Сервис предоставляет сведения, содержащиеся в ЕГРЮЛ или ЕГРИП, о государственной регистрации ЮЛ, ИП, крестьянских (фермерских) хозяйств, позволяет получить информацию об адресах массовой регистрации, сведения о физических лицах, являющихся руководителями или участниками нескольких организаций, об организациях, имеющих задолженность по уплате налогов и/или не предоставляющих отчетность более одного года.
Ниже представлен полный список услуг сервиса.
Проверьте, не рискует ли ваш бизнес?
Сведения о юридических лицах и индивидуальных предпринимателях, в отношении которых представлены документы для государственной регистрации, в том числе для государственной регистрации изменений, вносимых в учредительные документы юридического лица, и внесения изменений в сведения о юридическом лице, содержащиеся в ЕГРЮЛ
Сообщения юридических лиц, опубликованные в журнале «Вестник государственной регистрации» о принятии решений о ликвидации, о реорганизации, об уменьшении уставного капитала, о приобретении обществом с ограниченной ответственностью 20% уставного капитала другого общества, а также иные сообщения юридических лиц, которые они обязаны публиковать в соответствии с законодательством Российской Федерации
Сведения, опубликованные в журнале «Вестник государственной регистрации» о принятых регистрирующими органами решениях о предстоящем исключении недействующих юр. лиц из ЕГРЮЛ
лиц из ЕГРЮЛ
Поиск сведений в реестре дисквалифицированных лиц
Юридические лица, в состав исполнительных органов которых входят дисквалифицированные лица
Адреса, указанные при государственной регистрации в качестве места нахождения несколькими юридическими лицами
Сведения о лицах, в отношении которых факт невозможности участия (осуществления руководства) в организации установлен (подтвержден) в судебном порядке
Сведения о юридических лицах, имеющих задолженность по уплате налогов и/или не представляющих налоговую отчетность более года
Сведения о физических лицах, являющихся руководителями или учредителями (участниками) нескольких юридических лиц
Информация из банка данных исполнительных производств Федеральной службы судебных приставов
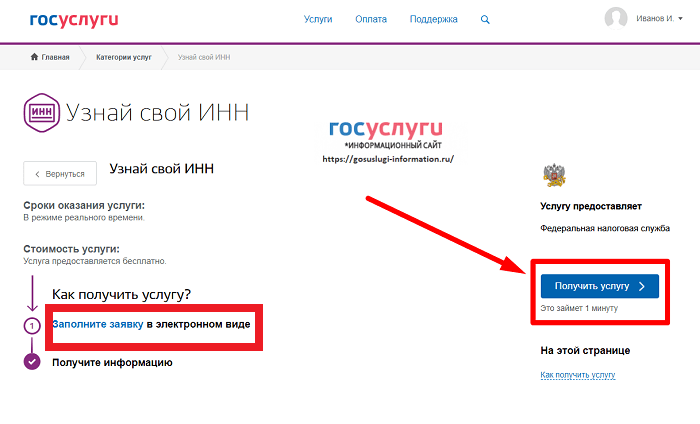
С помощью сервиса, предоставленного Федеральной налоговой службой, можно узнать ИНН физического лица
Для того, чтобы узнать ИНН физического лица необходимо:
1. заполнить форму запроса о наличии постановки на учет с присвоением ИНН;
2.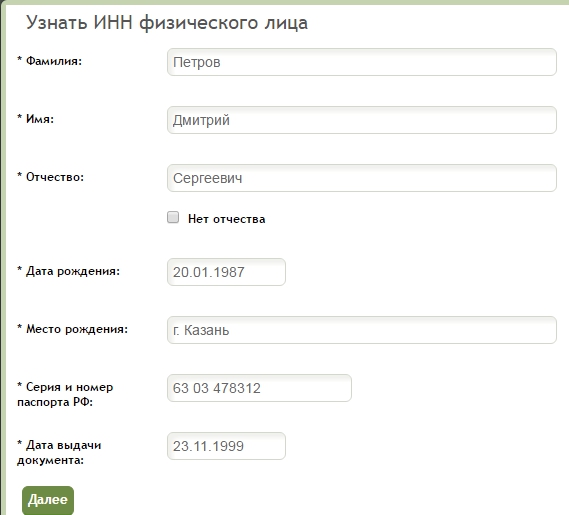 отправить запрос;
отправить запрос;
3. если физическое лицо состоит на учете в налоговых органах с присвоением ИНН, ИНН появится в строке результата.
Глубокое обучение (NN). Узнайте, как избежать провоза багажа… | by Michelle Xie
Узнайте, как избежать штрафов за ограничение багажа с помощью Deep Learning.
Я был недавно в аэропорту — заявление, которое я не думал, что смогу сделать еще год или около того. И я не знаю, как вы, ребята, но мне кажется, что я был проклят богами аэропорта, потому что по какой-то причине я никогда не смогу пройти регистрацию багажа без лишнего багажа. И это заставило меня задуматься, а что, если бы я мог использовать искусственный интеллект, чтобы упаковать для себя чемоданы.Что, если они могут помочь мне оптимизировать тип предметов, которые я хочу в своем багаже, а также управлять весом каждого предмета и ценностью или важностью каждого предмета для меня? Итак, я начал копаться и решил почитать о глубоком обучении…
Что такое глубокое обучение?
В течение долгого времени мне всегда было трудно понять, является ли глубокое обучение частью машинного обучения, или машинное обучение является частью глубокого обучения, или это две разные области ИИ, и лучшая аналогия, которую я могу придумать. — рассматривать машинное обучение как область психологии, а глубокое обучение — как область нейробиологии.Теперь и психология, и нейробиология изучают, как работает мозг. Психология больше фокусируется на проведении социальных экспериментов и наблюдении за поведением и взаимодействием людей, чтобы дать объяснение некоторым из предложенных теорий и гипотез, в то время как нейробиология обращается к биологии мозга, чтобы действительно понять, как мозг работает на этом биологическом уровне. Если мы применим это к машинному обучению и глубокому обучению, хотя они оба являются методами или техниками для создания интеллектуальных машин или интеллектуального программного обеспечения, машинное обучение больше фокусируется на применении хорошо известных статистических методов к данным для создания прогнозных моделей и глубокого обучения с другой стороны. Hand больше фокусируется на моделировании процесса принятия решений, который человеческий мозг производит для создания решающих или человеческих моделей интеллектуальных машин.
— рассматривать машинное обучение как область психологии, а глубокое обучение — как область нейробиологии.Теперь и психология, и нейробиология изучают, как работает мозг. Психология больше фокусируется на проведении социальных экспериментов и наблюдении за поведением и взаимодействием людей, чтобы дать объяснение некоторым из предложенных теорий и гипотез, в то время как нейробиология обращается к биологии мозга, чтобы действительно понять, как мозг работает на этом биологическом уровне. Если мы применим это к машинному обучению и глубокому обучению, хотя они оба являются методами или техниками для создания интеллектуальных машин или интеллектуального программного обеспечения, машинное обучение больше фокусируется на применении хорошо известных статистических методов к данным для создания прогнозных моделей и глубокого обучения с другой стороны. Hand больше фокусируется на моделировании процесса принятия решений, который человеческий мозг производит для создания решающих или человеческих моделей интеллектуальных машин.
Не волнуйтесь, я постараюсь не использовать слишком много сложной технической терминологии. В конце концов, мой словарный запас (в лучшем случае) все еще весьма ограничен, особенно в этой области.
В любом случае, как я уже говорил, глубокое обучение на самом деле связано с созданием искусственных нейронных сетей, имитирующих работу нашего мозга. Эти искусственные нейронные сети являются способом имитации того, как наши синапсы в нашем мозгу или нейроны в нашем мозгу могут запускаться и запускать другие нейроны, чтобы контролировать некоторые наши движения, реагировать на что-то или даже принимать решения.Это подводит меня к…
Что такое нейронные сети?
Вы имеете в виду эти страшно выглядящие диаграммы? На самом деле это не , а , страшный, как только вы его разберете, но они оказались довольно мощными и фактически являются основой многих действительно мощных и сложных технологий искусственного интеллекта в наши дни, таких как компьютерное зрение и обработка естественного языка, которые привело к тому, что научная фантастика, как беспилотные автомобили, стала реальностью.
Давайте тогда разберем нейронную сеть, не так ли?
Нейронные сети состоят из слоев нейронов.
Есть 3 типа слоев, о которых вам нужно знать: входной слой, скрытые слои и выходной слой.
Входной слой позволяет вам сопоставлять характеристики ваших данных как входных в нейронную сеть, выходной слой позволяет вам определять количество меток или классов, которые вы хотите, чтобы ваша нейронная сеть предсказывала или выводила, а затем все, что между ними…
Как вы уже догадались, спрятанный материал.
Итак, страшная диаграмма, с которой я начал, известна как полностью связанная нейронная сеть, потому что, как вы можете видеть, каждый нейрон (представленный одним из этих цветных кружков или узлов) в каждом слое связан с каждым из других нейронов в следующий слой закончился.
Хорошо, давайте вернемся к моей проблеме с избыточным весом и заменим эти узлы (или нейроны) чем-нибудь из моего чемодана:
Допустим, у меня есть некоторые функции данных, которые представляют мои чемоданы, например размер чемодана, марка чемодана, как долго чемодан будет в пути, какой авиакомпанией я летаю и т. д. Итак, я собираюсь сопоставить каждую из этих функций с входным узлом входного слоя. И давайте предположим, что мои скрытые слои состоят из одежды, которая вместе составляет наряд e.грамм. Мне нужен верх, низ и обувь. Я назову первый скрытый слой верхним слоем, второй скрытый слой — нижним слоем, а третий скрытый слой — слоем обуви. И, наконец, у меня есть выходной слой, который просто представляет выходные данные, которые я хочу от моей модели нейронной сети, которая в этом случае просто говорит мне, должен ли я упаковать или не упаковать определенную комбинацию одежды в свой чемодан, чтобы взять с собой в аэропорт. . Теперь давайте соединим эти слои вместе:
д. Итак, я собираюсь сопоставить каждую из этих функций с входным узлом входного слоя. И давайте предположим, что мои скрытые слои состоят из одежды, которая вместе составляет наряд e.грамм. Мне нужен верх, низ и обувь. Я назову первый скрытый слой верхним слоем, второй скрытый слой — нижним слоем, а третий скрытый слой — слоем обуви. И, наконец, у меня есть выходной слой, который просто представляет выходные данные, которые я хочу от моей модели нейронной сети, которая в этом случае просто говорит мне, должен ли я упаковать или не упаковать определенную комбинацию одежды в свой чемодан, чтобы взять с собой в аэропорт. . Теперь давайте соединим эти слои вместе:
Если вы когда-либо раньше выбирали одежду, вы знаете, что вы не можете просто выбрать верх, брюки и обувь одновременно, независимо от того, заботитесь ли вы о моде или нет.Обычно вы начинаете с одного элемента, выбираете следующий, следующий за ним и так далее. Иногда вы даже можете выбрать два или более предмета, пока окончательно не решите, что надеть. То же самое и с нейронной сетью. Вы начинаете с первого слоя, вы выбираете некоторые узлы или нейроны для активации, иногда вы можете активировать пару из них, а затем переходите на следующий слой, чтобы активировать узлы или нейроны в следующем слое, и это продолжается до тех пор, пока вы не достигнете результата. слой. Это называется прямым распространением.Вы перенаправляете некоторые из вариантов, которые вы сделали на предыдущих уровнях, на следующий слой, чтобы помочь нейронной сети решить, какие узлы запускать следующими, на основе некоторых промежуточных решений, которые вы уже приняли.
То же самое и с нейронной сетью. Вы начинаете с первого слоя, вы выбираете некоторые узлы или нейроны для активации, иногда вы можете активировать пару из них, а затем переходите на следующий слой, чтобы активировать узлы или нейроны в следующем слое, и это продолжается до тех пор, пока вы не достигнете результата. слой. Это называется прямым распространением.Вы перенаправляете некоторые из вариантов, которые вы сделали на предыдущих уровнях, на следующий слой, чтобы помочь нейронной сети решить, какие узлы запускать следующими, на основе некоторых промежуточных решений, которые вы уже приняли.
Теперь предположим, что после одной итерации наша нейронная сеть активирует нейроны в нашей сети следующим образом:
Итак, наша нейронная сеть сказала нам упаковать комбинацию одежды в чемодан №1. Но когда мы добираемся до аэропорта, мы обнаруживаем, что наш багаж все еще избыточный, или он упаковал незаконное содержимое в сумку, или, что еще хуже … он упаковал для вас неподходящую одежду. Какая катастрофа для вашего Instagram!
Какая катастрофа для вашего Instagram!
В общем, наша модель ошиблась.
Что мы можем с этим поделать?
Что ж, чтобы убедиться, что наша нейронная сеть может помочь нам упаковать правильный чемодан, нам нужно будет выполнить несколько итераций для обучения нейронной сети, и во время каждой итерации нам может потребоваться настроить веса и смещение нейронов в наша модель.
Веса и смещения?
Думайте о весе и смещении как о важности и предпочтении предмета в вашем чемодане.Допустим, чтобы собрать чемоданы для верхнего слоя, вы можете выбрать из 5 разных футболок, 5 разных майок и 5 разных рубашек с длинным рукавом. Как теперь решить, нужны ли вам футболки, майки или рубашки с длинным рукавом? Вы, вероятно, собираетесь проверить пункт назначения. Если место назначения будет жарким, вы, вероятно, отдадите предпочтение футболкам и майкам. Если место назначения холодное, вы, вероятно, отдадите предпочтение рубашкам с длинным рукавом. Точно так же вам нужно будет обучить нейронную сеть тому, что ей нужно расставить для вас по приоритетам, с помощью весов.Теперь, даже среди рубашек, майок и с длинными рукавами, вы, вероятно, предпочитаете один топ другому, потому что, честно говоря, у всех есть фавориты. В этом случае вы можете использовать смещение, чтобы настроить модель в пользу узлов, которые содержат ваши любимые элементы.
Точно так же вам нужно будет обучить нейронную сеть тому, что ей нужно расставить для вас по приоритетам, с помощью весов.Теперь, даже среди рубашек, майок и с длинными рукавами, вы, вероятно, предпочитаете один топ другому, потому что, честно говоря, у всех есть фавориты. В этом случае вы можете использовать смещение, чтобы настроить модель в пользу узлов, которые содержат ваши любимые элементы.
Как мы активируем эти нейроны или узлы?
После того, как kdrama закончилась, чтобы поплакать, я решил усложнить задачу с помощью забавной математики из этой лекции и выяснил, что нейрон на самом деле состоит из линейной части и части активации, которую мы можем представить как:
нейрон = линейный + активация
Думайте о линейной части как о константе, поэтому то, что действительно запускает нейрон, — это компонент активации, который определяется функцией активации.Теперь функция активации зависит от 3 вещей: характеристики, веса и смещения.
Активировать или, Не активировать?
Давайте возьмем наш первый скрытый слой в качестве примера:
В этом слое всего два узла или нейрона, например футболка A и футболка B. Теперь, чтобы решить, хотим ли мы выстрелить футболкой A, нам нужно посмотреть на значение, возвращаемое функцией активации (y1), которая затем определит общее значение этого нейрона. То же самое и с футболкой B (y2).
Теперь, когда символ σ, который выглядит как ‘о’ с классной прической, представляет сигмовидную кривую, которая по своей природе может принимать любое число от отрицательной бесконечности ( -∞ ) до бесконечности ( ∞ ) и сопоставьте его с некоторым значением от 0 до 1, что, на мой взгляд, довольно круто. Но он делает больше, чем просто быть крутым, означает, что мы можем взять любое число и представить его в стандартном конечном диапазоне значений от 0 до 1, если мы игнорируем тот факт, что на самом деле существуют маленькие бесконечности в диапазоне от 0 до 1 но дело не в этом.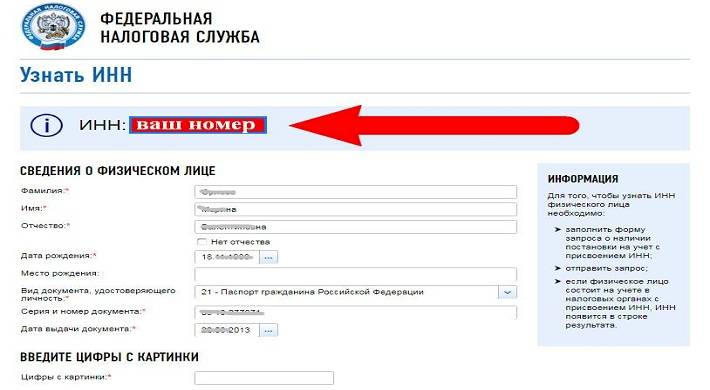 Дело в том, что теперь мы можем установить некоторые границы, например, 0,5, поэтому, если наш y1 возвращает что-либо в диапазоне от 0,5 до 1, мы запускаем нейрон A футболки. И если y1 возвращает что-нибудь в диапазоне от 0 до 0,4999…, мы не запускаем нейрон футболки.
Дело в том, что теперь мы можем установить некоторые границы, например, 0,5, поэтому, если наш y1 возвращает что-либо в диапазоне от 0,5 до 1, мы запускаем нейрон A футболки. И если y1 возвращает что-нибудь в диапазоне от 0 до 0,4999…, мы не запускаем нейрон футболки.
То же самое и с футболкой B. Итак, наша маленькая буква «о» с крутой прической (σ) отлично подходит для задач двоичной классификации, например, активировать или не активировать.
Хорошо, поэтому мы можем настроить веса и смещение в нейронах модели, но как нам определить, какие значения нужно настроить?
Введение в функции потерь
Без какой-либо помощи мы с вами, вероятно, потеряемся в равной степени, когда дело дойдет до выбора того, какие веса и смещения выбрать для нашей модели, поэтому нам понадобится нечто, называемое функцией потерь (или функцией стоимости) чтобы помочь нам.Функция потерь сообщает нам, насколько далеко предсказанные значения нашей модели были по сравнению с фактическими значениями.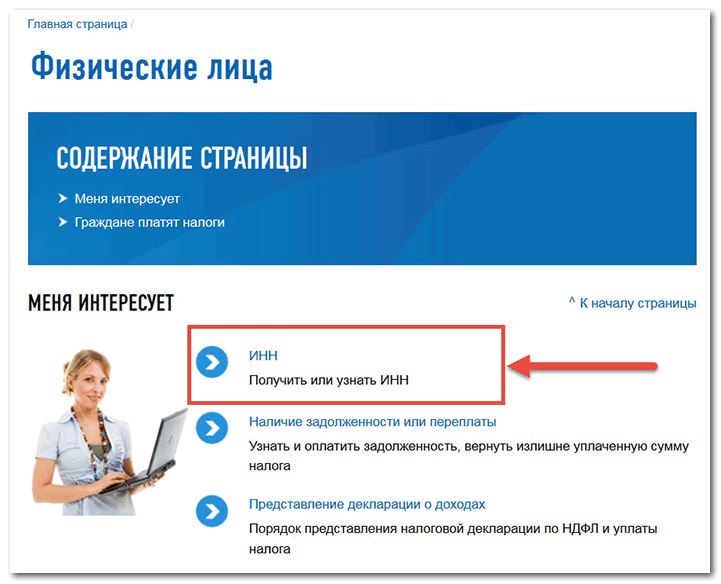 Чтобы найти это, мы могли бы вычислить положительную разницу между фактическим значением (y) и прогнозируемым значением (ŷ ) или суммировать квадраты дисперсий двух значений:
Чтобы найти это, мы могли бы вычислить положительную разницу между фактическим значением (y) и прогнозируемым значением (ŷ ) или суммировать квадраты дисперсий двух значений:
потеря = фактическое - прогнозируемое = | y - ŷ | или ∑ (y - ŷ) ²
Да ладно, но как это нам поможет?
Что ж, если мы знаем, насколько наша модель отклоняется, мы можем попытаться настроить эти значения весов и смещения (параметры в нашей модели), чтобы мы могли уменьшить количество потерь (или ошибочности), которые есть в нашей модели. модель.По сути, мы хотим сократить разрыв между прогнозируемыми значениями модели и фактическими значениями. Другими словами, минимизируйте значение, возвращаемое нашей функцией потерь. Теперь, если мы вернемся к математике средней школы, вспомним, когда мы узнали, как вычислить производную функции, чтобы найти наклон или скорость изменения функции? Если вы этого не помните, это нормально, мое «я» от 16 до 17 лет тоже очень серьезно оценивает мои текущие навыки вычисления прямо сейчас, и представьте, что вас судит ваше собственное подростковое «я»!
В любом случае, мы хотим найти производную нашей функции потерь, чтобы найти оптимальные значения параметров весов и смещения, чтобы настроить нашу модель. Эти производные называются оптимизаторами. Чтобы попытаться достичь оптимального значения, мы хотим, чтобы производная нашей функции потерь была равна 0, поэтому наклон функции должен быть плоским. Именно тогда мы знаем, что достигли локального оптимума этой функции.
Эти производные называются оптимизаторами. Чтобы попытаться достичь оптимального значения, мы хотим, чтобы производная нашей функции потерь была равна 0, поэтому наклон функции должен быть плоским. Именно тогда мы знаем, что достигли локального оптимума этой функции.
В контексте нашей проблемы с багажом представим, что наш чемодан является функцией потерь, а масштаб — производной функции потерь. Теперь, если мы поместим наш чемодан на весы (например, возьмем производную функции), мы можем обнаружить, что в настоящее время он недовес (например.грамм. производная отрицательна), это означает, что мы все еще можем добавить в чемодан больше предметов. Другими словами, у нас все еще есть место для увеличения веса нашего чемодана, пока он не достигнет оптимального веса (ограничения веса, установленного этой авиакомпанией). Точно так же, если наша функция возрастает, то есть производная нашей функции потерь положительна, нам нужно будет уменьшить вес, чтобы достичь оптимального значения 0 потерь.
Обычно мы используем оптимизаторы, чтобы узнать оптимальные значения веса и смещения наших нейронов, а затем передаем эти значения обратно в нашу модель.Этот процесс называется обратным распространением, потому что мы начинаем с последнего слоя и решаем, на какие значения настраивать наши параметры веса и смещения, затем мы перемещаем слой назад и делаем то же самое, а затем просто продолжаем двигаться назад по слоям, чтобы настроить наши параметры. параметры, так что, надеюсь, при прохождении еще одной итерации нашей нейронной сети мы сможем получить прогнозируемое значение, которое намного ближе к нашему фактическому значению.
Почему мы начинаем со спины?
Приходилось ли вам когда-нибудь переупаковывать чемоданы в аэропорту? Потому что у меня это не весело.Лучший способ всегда начинать с того, что снимать предметы с верхнего слоя чемодана, пытаться втиснуть их в ручную кладь, прежде чем снимать предметы со следующего уровня ниже, вместо того, чтобы выливать все содержимое в чемодан, а затем снова упаковывать все из начало. Проходя через чемодан обратно, вы лучше понимаете, какие предметы нужно убрать. В случае нейронных сетей обратное распространение помогает вам решить, насколько настраивать ваши параметры, потому что все уровни, предшествующие этому, передаются на более поздние уровни.Это похоже на то, как более ранние предметы, которые вы, возможно, упаковали, будут определять, сколько места у вас осталось, чтобы упаковать некоторые из ваших оставшихся предметов.
Проходя через чемодан обратно, вы лучше понимаете, какие предметы нужно убрать. В случае нейронных сетей обратное распространение помогает вам решить, насколько настраивать ваши параметры, потому что все уровни, предшествующие этому, передаются на более поздние уровни.Это похоже на то, как более ранние предметы, которые вы, возможно, упаковали, будут определять, сколько места у вас осталось, чтобы упаковать некоторые из ваших оставшихся предметов.
«Ваш самолет сейчас садится у выхода…»
В любом случае, мне пора. Существует много разных типов нейронных сетей, и я почти не коснулся поверхности искусственных нейронных сетей. Просто знайте, что глубокое обучение — это хорошо изученная и развивающаяся область в области ИИ в основном потому, что некоторые из его приложений имеют огромные коммерческие преимущества и успех.Если вы хотите узнать больше о глубоком обучении, посетите платформу Microsoft Learn. Там много бесплатного контента, который в основном охватывает все и вся, и я уже упоминал… это бесплатно?
О да, и прежде чем я уйду, я должен упомянуть, что у меня также есть аккаунт в Твиттере, который я на самом деле не использую, но у меня есть один, если вы хотите подписаться на меня (@mishxie). Может быть, вы научите меня нескольким советам и уловкам, как правильно пользоваться Twitter.
Может быть, вы научите меня нескольким советам и уловкам, как правильно пользоваться Twitter.
Как всегда, приветствуются все отзывы, будь то положительные, нейтральные или отрицательные 😊
Надо бежать, будьте осторожны!
Найдите сумму ряда $ \ sum \ frac {1} {n (n + 1) (n + 2)} $
Позвольте мне добавить более общий ответ.\ infty {{1 \ over {n \ left ({n + 1} \ right) \ left ({n + 2} \ right)}}} = {1 \ более 4} \ cr}
$Вычислить n + nn + nnn + … + n (m раз) в Python
Вычислить n + nn + nnn +… + n (m раз) в Python
Программа должна найти математический ряд, в котором нам нужно принять значения n и m. n — базовое число, а m — количество раз, до которого выполняется серия.
Примеры:
Ввод: 2 + 22 + 222 + 2222 + 22222 Выход: 24690 Ввод: 12 + 1212 + 121212 Выход: 122436
Сначала мы конвертируем числа в строковый формат и регулярно соединяем их. Позже мы конвертируем их обратно в целые числа и складываем до m-го члена. как показано в следующей программе.
Позже мы конвертируем их обратно в целые числа и складываем до m-го члена. как показано в следующей программе.
|
Выход:
24690
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
python — как установить значения для слоев в pytorch nn.module?
У меня есть модель, которую я пытаюсь заставить работать. Я работаю над ошибками, но теперь думаю, что дело дошло до значений в моих слоях. Я получаю эту ошибку:
RuntimeError: данные группы = 1, вес размером 24 1 3 3, ожидаемый вход [512, 50, 50, 3] будет иметь 1 канал,
но вместо этого получил 50 каналов
Мои параметры:
LR = 5e-2
N_EPOCHS = 30
BATCH_SIZE = 512
ВЫПАДЕНИЕ = 0.5
Информация о моем изображении:
глубина = 24
каналы = 3
исходная высота = 1600
исходная ширина = 1200
изменен до 50x50
Это размер моих данных:
Форма поезда (743, 50, 50, 3) (743, 7)
Форма для теста (186, 50, 50, 3) (186, 7)
Пиксели поезда 0255 188. 12228712427097 61.49539262385051
Тестовые пиксели 0255 189,35559211469533 60,688278787628775
12228712427097 61.49539262385051
Тестовые пиксели 0255 189,35559211469533 60,688278787628775
 12228712427097 61.49539262385051
Тестовые пиксели 0255 189,35559211469533 60,688278787628775
12228712427097 61.49539262385051
Тестовые пиксели 0255 189,35559211469533 60,688278787628775
Я заглянул сюда, чтобы попытаться понять, какие значения ожидает каждый слой, но когда я вставил то, что здесь написано, https: // todatascience.com / pytorch-layer-sizes-what-sizes-should-they-be-and-why-4265a41e01fd, это дает мне ошибки о неправильных каналах и ядрах.
Я обнаружил, что torch_summary дает мне больше информации о результатах, но он вызывает больше вопросов.
Это мой torch_summary код:
из импортных моделей torchvision
из torchсводка импорта
импортный фонарик
импортировать torch.nn как nn
класс CNN (nn.Module):
def __init __ (сам):
super (CNN, сам) .__ init __ ()
себя.conv1 = nn.Conv2d (1,24, kernel_size = 5) # вывод (n_examples, 16, 26, 26)
self.convnorm1 = nn.BatchNorm2d (24) # каналы из предыдущего слоя
self.pool1 = nn.MaxPool2d ((2, 2)) # вывод (n_examples, 16, 13, 13)
self. conv2 = nn.Conv2d (24,48, kernel_size = 5) # вывод (n_examples, 32, 11, 11)
self.convnorm2 = nn.BatchNorm2d (48) # 2 * каналы?
self.pool2 = nn.AvgPool2d ((2, 2)) # вывод (n_examples, 32, 5, 5)
self.linear1 = nn.Linear (400,120) # ввод будет сведен к (n_examples, 32 * 5 * 5)
себя.linear1_bn = nn.BatchNorm1d (400) # особенности?
self.drop = nn.Dropout (ВЫПАДЕНИЕ)
self.linear2 = nn.Linear (400, 10)
self.act = torch.relu
def вперед (self, x):
x = self.pool1 (self.convnorm1 (self.act (self.conv1 (x))))
x = self.pool2 (self.convnorm2 (self.act (self.conv2 (x))))
x = self.drop (self.linear1_bn (self.act (self.linear1 (x.view (len (x), -1)))))
вернуть self.linear2 (x)
device = torch.device ("cuda: 0", если torch.cuda.is_available () иначе "cpu")
модель = CNN ().к (устройству)
резюме (модель, (3, 50, 50))
 conv2 = nn.Conv2d (24,48, kernel_size = 5) # вывод (n_examples, 32, 11, 11)
self.convnorm2 = nn.BatchNorm2d (48) # 2 * каналы?
self.pool2 = nn.AvgPool2d ((2, 2)) # вывод (n_examples, 32, 5, 5)
self.linear1 = nn.Linear (400,120) # ввод будет сведен к (n_examples, 32 * 5 * 5)
себя.linear1_bn = nn.BatchNorm1d (400) # особенности?
self.drop = nn.Dropout (ВЫПАДЕНИЕ)
self.linear2 = nn.Linear (400, 10)
self.act = torch.relu
def вперед (self, x):
x = self.pool1 (self.convnorm1 (self.act (self.conv1 (x))))
x = self.pool2 (self.convnorm2 (self.act (self.conv2 (x))))
x = self.drop (self.linear1_bn (self.act (self.linear1 (x.view (len (x), -1)))))
вернуть self.linear2 (x)
device = torch.device ("cuda: 0", если torch.cuda.is_available () иначе "cpu")
модель = CNN ().к (устройству)
резюме (модель, (3, 50, 50))
conv2 = nn.Conv2d (24,48, kernel_size = 5) # вывод (n_examples, 32, 11, 11)
self.convnorm2 = nn.BatchNorm2d (48) # 2 * каналы?
self.pool2 = nn.AvgPool2d ((2, 2)) # вывод (n_examples, 32, 5, 5)
self.linear1 = nn.Linear (400,120) # ввод будет сведен к (n_examples, 32 * 5 * 5)
себя.linear1_bn = nn.BatchNorm1d (400) # особенности?
self.drop = nn.Dropout (ВЫПАДЕНИЕ)
self.linear2 = nn.Linear (400, 10)
self.act = torch.relu
def вперед (self, x):
x = self.pool1 (self.convnorm1 (self.act (self.conv1 (x))))
x = self.pool2 (self.convnorm2 (self.act (self.conv2 (x))))
x = self.drop (self.linear1_bn (self.act (self.linear1 (x.view (len (x), -1)))))
вернуть self.linear2 (x)
device = torch.device ("cuda: 0", если torch.cuda.is_available () иначе "cpu")
модель = CNN ().к (устройству)
резюме (модель, (3, 50, 50))
Вот что он мне дал:
Файл "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/conv. py", строка 342, в conv2d_forward
self.padding, self.dilation, self.groups)
RuntimeError: данные группы = 1, вес размером 24 1 5 5, ожидаемый вход [2, 3, 50, 50] будет иметь 1 канал, но вместо этого получил 3 канала.
 py", строка 342, в conv2d_forward
self.padding, self.dilation, self.groups)
RuntimeError: данные группы = 1, вес размером 24 1 5 5, ожидаемый вход [2, 3, 50, 50] будет иметь 1 канал, но вместо этого получил 3 канала.
py", строка 342, в conv2d_forward
self.padding, self.dilation, self.groups)
RuntimeError: данные группы = 1, вес размером 24 1 5 5, ожидаемый вход [2, 3, 50, 50] будет иметь 1 канал, но вместо этого получил 3 канала.
Когда я запускаю весь свой код и unqueeze_ (0) мои данные, вот так …. x_train = torch.from_numpy (x_train).unsqueeze_ (0) Я получаю эту ошибку:
Файл "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/conv.py", строка 342, в conv2d_forward
self.padding, self.dilation, self.groups)
RuntimeError: ожидается 4-мерный ввод для 4-мерного веса 24 1 5 5, но вместо этого получен 5-мерный ввод размера [1, 743, 50, 50, 3]
Я не знаю, как понять, как ввести правильные значения в слои. Кто-нибудь, пожалуйста, поможет мне найти правильные значения и понять, как это понимать? Я знаю, что выход одного слоя должен быть входом другого слоя.Ничто не соответствует тому, что я думал, что знал. Заранее спасибо!!
Нейронные сети— документация по PyTorch 1.
 7.1
7.1Примечание
Щелкните здесь, чтобы загрузить полный пример кода
Нейронные сети можно построить с помощью пакета torch.nn .
Теперь, когда вы взглянули на autograd , nn зависит от autograd для определения моделей и их различения.
Модуль nn.Module содержит слои, а метод forward (ввод) , который
возвращает результат .
Например, посмотрите на эту сеть, которая классифицирует цифровые изображения:
свёрточная сеть
Это простая сеть прямого распространения. Он принимает вход, кормит его через несколько слоев один за другим, а затем, наконец, дает выход.
Типичная процедура обучения нейронной сети выглядит следующим образом:
- Определите нейронную сеть с некоторыми изучаемыми параметрами (или веса)
- Итерация набора входных данных
- Обработка ввода через сеть
- Вычислить потерю (насколько результат не верен)
- Распространение градиентов обратно в параметры сети
- Обновите веса сети, обычно используя простое правило обновления:
вес = вес - скорость обучения * градиент
Определите сеть
Определим эту сеть:
импортная горелка импортный фонарик.
 nn как nn
импортировать torch.nn.functional как F
класс Net (nn.Module):
def __init __ (сам):
super (Net, self) .__ init __ ()
# 1 входной канал изображения, 6 выходных каналов, квадратная свертка 3x3
# ядро
self.conv1 = nn.Conv2d (1, 6, 3)
self.conv2 = nn.Conv2d (6, 16, 3)
# аффинная операция: y = Wx + b
self.fc1 = nn.Linear (16 * 6 * 6, 120) # 6 * 6 от размера изображения
self.fc2 = nn.Linear (120, 84)
self.fc3 = nn.Linear (84, 10)
def вперед (self, x):
# Максимальное объединение в (2, 2) окне
х = F.max_pool2d (F.relu (self.conv1 (x)), (2, 2))
# Если размер - квадрат, вы можете указать только одно число
x = F.max_pool2d (F.relu (self.conv2 (x)), 2)
x = x.view (-1, self.num_flat_features (x))
х = F.relu (self.fc1 (x))
х = F.relu (self.fc2 (x))
х = self.fc3 (х)
вернуть х
def num_flat_features (self, x):
size = x.size () [1:] # все измерения, кроме измерения пакета
num_features = 1
для размера s:
num_features * = s
вернуть num_features
net = Net ()
печать (нетто)
nn как nn
импортировать torch.nn.functional как F
класс Net (nn.Module):
def __init __ (сам):
super (Net, self) .__ init __ ()
# 1 входной канал изображения, 6 выходных каналов, квадратная свертка 3x3
# ядро
self.conv1 = nn.Conv2d (1, 6, 3)
self.conv2 = nn.Conv2d (6, 16, 3)
# аффинная операция: y = Wx + b
self.fc1 = nn.Linear (16 * 6 * 6, 120) # 6 * 6 от размера изображения
self.fc2 = nn.Linear (120, 84)
self.fc3 = nn.Linear (84, 10)
def вперед (self, x):
# Максимальное объединение в (2, 2) окне
х = F.max_pool2d (F.relu (self.conv1 (x)), (2, 2))
# Если размер - квадрат, вы можете указать только одно число
x = F.max_pool2d (F.relu (self.conv2 (x)), 2)
x = x.view (-1, self.num_flat_features (x))
х = F.relu (self.fc1 (x))
х = F.relu (self.fc2 (x))
х = self.fc3 (х)
вернуть х
def num_flat_features (self, x):
size = x.size () [1:] # все измерения, кроме измерения пакета
num_features = 1
для размера s:
num_features * = s
вернуть num_features
net = Net ()
печать (нетто)
Вне:
Нетто ( (conv1): Conv2d (1, 6, размер_ядра = (3, 3), stride = (1, 1)) (conv2): Conv2d (6, 16, размер_ядра = (3, 3), stride = (1, 1)) (fc1): линейный (in_features = 576, out_features = 120, bias = True) (fc2): линейный (in_features = 120, out_features = 84, bias = True) (fc3): линейный (in_features = 84, out_features = 10, bias = True) )
Вам просто нужно определить функцию вперед и назад функция (где вычисляются градиенты) автоматически определяется для вас
с использованием автограда . Вы можете использовать любую из тензорных операций в функции
Вы можете использовать любую из тензорных операций в функции forward .
Обучаемые параметры модели возвращаются функцией net.parameters ()
params = список (net.parameters ()) печать (len (параметры)) print (params [0] .size ()) # Вес конв1.
Вне:
10 torch.Size ([6, 1, 3, 3])
Давайте попробуем случайный ввод 32×32. Примечание: ожидаемый размер входа этой сети (LeNet) — 32×32. Чтобы использовать эту сеть на набор данных MNIST, пожалуйста, измените размер изображений из набора данных на 32×32.
вход = torch.randn (1, 1, 32, 32) out = net (ввод) распечатывать)
Вне:
тензор ([[0,1464, 0,0673, -0,0185, 0,0048, 0,1427, -0,0866, -0,0237, -0,0991,
-0.0903, 0.0886]], grad_fn = )
Обнулить градиентные буферы всех параметров и задних параметров со случайным градиенты:
net.zero_grad () out.backward (torch.randn (1, 10))
Примечание
torch. поддерживает только мини-партии. Весь факел 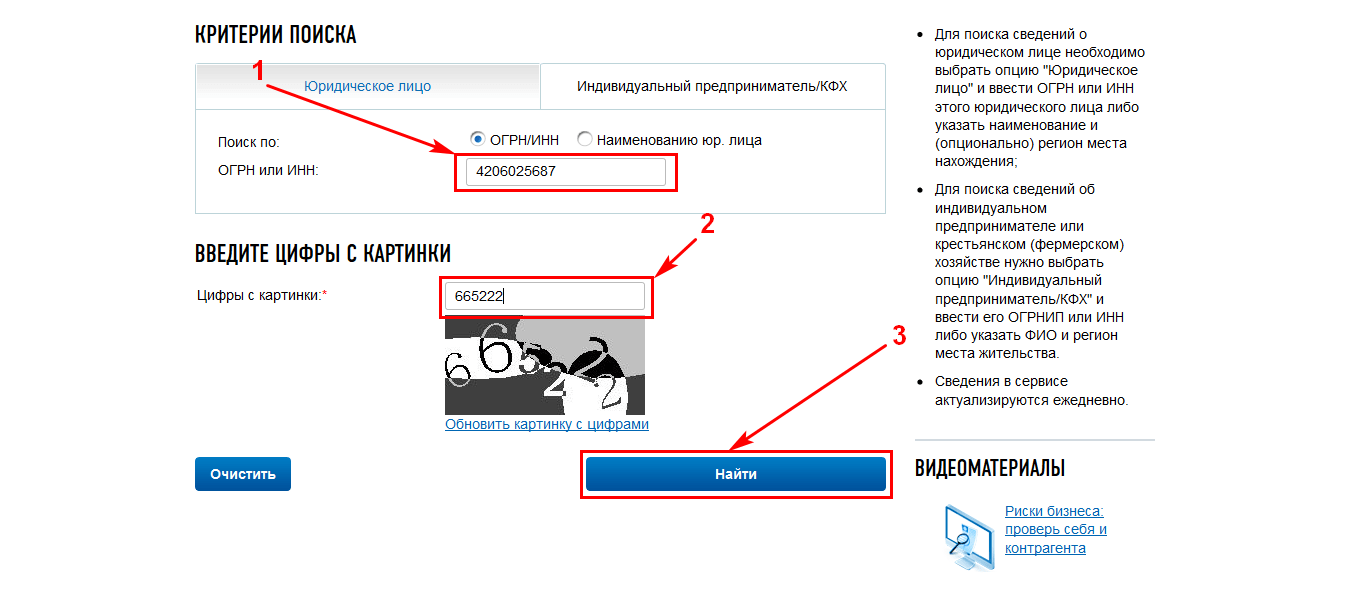 nn
nn .№ пакет поддерживает только вводы, которые представляют собой мини-серию образцов, а не
единичный образец.
Например, nn.Conv2d примет 4D тензор nSamples x nChannels x высота x ширина .
Если у вас один сэмпл, просто используйте input.unsqueeze (0) , чтобы добавить
поддельный размер партии.
Прежде чем продолжить, давайте вспомним все классы, которые вы уже видели.
- Резюме:
-
резак.Tensor— многомерный массив с поддержкой автограда такие операции, какbackward (). Также поддерживает уклон w.r.t. в тензор. -
nn.Module— Модуль нейронной сети. Удобный способ инкапсулирующие параметры с помощниками для их переноса в GPU, экспорт, загрузка и др. -
nn. Параметр— своего рода тензор, то есть автоматически регистрируется как параметр при назначении в качестве атрибута дляМодуль. -
autograd.Function— Реализует прямое и обратное определения автограда . Каждая операцияTensorсоздает на как минимум один узелFunction, который подключается к функциям, которые создалTensorи кодирует его историю .
-
- На данный момент мы охватили:
- Определение нейронной сети
- Обработка входных данных и обратный вызов
- Осталось:
- Расчет убытка
- Обновление весов сети

Функция потерь
Функция потерь принимает пару входов (выход, цель) и вычисляет значение, оценивающее, насколько далеко выход от цели.
Есть несколько разных
функции потерь при
nn пакет.
Простая потеря: nn.MSELoss , которая вычисляет среднеквадратичную ошибку.
между входом и целью.
Например:
выход = нетто (вход) target = torch.
 randn (10) # фиктивная цель, например
target = target.view (1, -1) # сделать ту же форму, что и output
критерий = nn.MSELoss ()
потеря = критерий (результат, цель)
печать (потеря)
randn (10) # фиктивная цель, например
target = target.view (1, -1) # сделать ту же форму, что и output
критерий = nn.MSELoss ()
потеря = критерий (результат, цель)
печать (потеря)
Вне:
тензор (1.0942, grad_fn =)
Теперь, если вы проследите убыток в обратном направлении, используя его .Grad_fn , вы увидите график вычислений, который выглядит
как это:
вход -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> вид -> линейный -> relu -> linear -> relu -> linear
-> MSELoss
-> потеря
Итак, когда мы вызываем loss.backward () , весь граф дифференцируется
w.r.t. потери и все тензоры в графе, у которого requires_grad = True будет их .grad Накопленный тензор с градиентом.
Для наглядности сделаем несколько шагов назад:
print (loss.grad_fn) # MSELoss print (loss.grad_fn.next_functions [0] [0]) # Линейный print (loss.
 grad_fn.next_functions [0] [0] .next_functions [0] [0]) # ReLU
grad_fn.next_functions [0] [0] .next_functions [0] [0]) # ReLU
Вне:
<объект MseLossBackward в 0x7f4d2beb6198> <Объект AddmmBackward по адресу 0x7f4d2beb6a58> <Объект AccumulateGrad по адресу 0x7f4d2beb6a58>
Обратное соединение
Для обратного распространения ошибки все, что нам нужно сделать, это потерять .назад () .
Однако вам необходимо очистить существующие градиенты, иначе градиенты будут
накапливаются до существующих градиентов.
Теперь мы вызовем loss.backward () и посмотрим на смещение conv1.
градиенты до и после обратного.
net.zero_grad () # обнуляет градиентные буферы всех параметров
print ('conv1.bias.grad перед обратным')
печать (net.conv1.bias.grad)
loss.backward ()
print ('conv1.bias.grad после обратного')
печать (net.conv1.bias.grad)
Вне:
усл.bias.grad перед обратным тензор ([0., 0., 0., 0., 0., 0.]) conv1.bias.grad после обратного тензор ([- 0,0068, -0,0244, 0,0278, -0,0142, 0,0111, -0,0078])
Теперь мы увидели, как использовать функции потерь.
Прочитать позже:
Пакет нейронной сети содержит различные модули и функции потерь. которые образуют строительные блоки глубоких нейронных сетей. Полный список с документация здесь.
Осталось выучить:
- Обновление весов сети
Обновить вес
Самым простым правилом обновления, используемым на практике, является стохастический градиент. Спуск (SGD):
вес = вес - скорость обучения * градиент
Мы можем реализовать это, используя простой код Python:
скорость обучения = 0.01
для f в net.parameters ():
f.data.sub_ (f.grad.data * скорость обучения)
Однако, поскольку вы используете нейронные сети, вы хотите использовать различные
такие правила обновления, как SGD, Nesterov-SGD, Adam, RMSProp и др.
Для этого мы создали небольшой пакет: torch.optim , который
реализует все эти методы. Пользоваться им очень просто:
Пользоваться им очень просто:
импортировать torch.optim as optim # создайте свой оптимизатор optimizer = optim.SGD (net.parameters (), lr = 0,01) # в вашем цикле обучения: оптимизатор.zero_grad () # обнуляем градиентные буферы output = net (ввод) потеря = критерий (результат, цель) loss.backward () optimizer.step () # Выполняет ли обновление
Примечание
Обратите внимание, как градиентные буферы нужно было вручную установить на ноль с помощью optimizer.zero_grad () . Это потому, что градиенты накапливаются
как описано в разделе Backprop.
Общее время работы скрипта: (0 минут 0,044 секунды)
Галерея создана Sphinx-Gallery
Юзабилити 101: Введение в юзабилити
Эту статью следует передать своему начальнику или любому, у кого мало времени, но которому необходимо знать основные факты юзабилити.
What — определение юзабилити
Удобство использования — это атрибут качества , который оценивает, насколько просты пользовательские интерфейсы. Слово «удобство использования» также относится к методам повышения простоты использования в процессе проектирования.
Слово «удобство использования» также относится к методам повышения простоты использования в процессе проектирования.
Удобство использования определяется 5 компонентами качества :
- Обучаемость : Насколько легко пользователям выполнять базовые задачи при первом знакомстве с дизайном?
- Эффективность : Как быстро пользователи смогут выполнять задачи после того, как изучат дизайн?
- Запоминаемость : Когда пользователи возвращаются к дизайну после периода, когда они не использовали его, насколько легко они могут восстановить свои навыки?
- Ошибки : Сколько ошибок делают пользователи, насколько серьезны эти ошибки и насколько легко они могут исправить ошибки?
- Satisfaction : Насколько приятно пользоваться дизайном?
Есть много других важных атрибутов качества.Ключевой из них является утилита , которая относится к функциональности дизайна: выполняет ли она то, что нужно пользователям?
Удобство использования и полезность одинаково важны и вместе определяют, будет ли что-то полезным: неважно, что что-то легко, если это не то, что вы хотите. Также бесполезно, если система гипотетически может делать то, что вы хотите, но вы не можете этого добиться, потому что пользовательский интерфейс слишком сложен. Чтобы изучить полезность дизайна, вы можете использовать те же методы исследования пользователей, которые улучшают удобство использования.
Также бесполезно, если система гипотетически может делать то, что вы хотите, но вы не можете этого добиться, потому что пользовательский интерфейс слишком сложен. Чтобы изучить полезность дизайна, вы можете использовать те же методы исследования пользователей, которые улучшают удобство использования.
- Определение Utility = предоставляет ли она необходимые вам функции .
- Определение Удобство использования = насколько легко и приятно использовать эти функции.
- Определение Полезный = юзабилити + полезность .
Почему важно удобство использования
В Интернете удобство использования — необходимое условие выживания. Если веб-сайтом сложно пользоваться, человек уходят из .Если на домашней странице нет четкого указания, что предлагает компания и что пользователи могут делать на сайте, люди покидают . Если пользователи теряются на сайте, они оставляют . Если информация на сайте трудночитаема или не отвечает на ключевые вопросы пользователей, они оставляют , а . Обратите внимание на закономерность? Нет такой вещи, как пользователь, читающий руководство по веб-сайту или иным образом тратящий много времени на то, чтобы разобраться в интерфейсе. Доступно множество других веб-сайтов; уход — это первая линия защиты, когда пользователи сталкиваются с трудностями.
Если пользователи теряются на сайте, они оставляют . Если информация на сайте трудночитаема или не отвечает на ключевые вопросы пользователей, они оставляют , а . Обратите внимание на закономерность? Нет такой вещи, как пользователь, читающий руководство по веб-сайту или иным образом тратящий много времени на то, чтобы разобраться в интерфейсе. Доступно множество других веб-сайтов; уход — это первая линия защиты, когда пользователи сталкиваются с трудностями.
Первый закон электронной коммерции заключается в том, что если пользователи не могут найти продукт, они не могут купить его .
Для интрасетей удобство использования зависит от производительности сотрудников. Время, потраченное пользователями на то, что они теряются в вашей интрасети или обдумывание сложных инструкций, — это деньги, которые вы тратите, платя им за то, чтобы они работали, не выполняя работу.
Современные передовые практики требуют тратить около 10% бюджета дизайн-проекта на удобство использования. В среднем это более чем удвоит желаемые показатели качества веб-сайта (что дает показатель улучшения 2,6) и чуть менее чем удвоит показатели качества интрасети. Что касается программного обеспечения и физических продуктов, улучшения обычно меньше, но все же существенны, если вы подчеркиваете удобство использования в процессе проектирования.
В среднем это более чем удвоит желаемые показатели качества веб-сайта (что дает показатель улучшения 2,6) и чуть менее чем удвоит показатели качества интрасети. Что касается программного обеспечения и физических продуктов, улучшения обычно меньше, но все же существенны, если вы подчеркиваете удобство использования в процессе проектирования.
Для проектов внутреннего дизайна подумайте об увеличении удобства использования вдвое, как о сокращении бюджета на обучение вдвое и удвоении количества операций, которые сотрудники выполняют в час.Для внешнего дизайна подумайте об удвоении продаж, удвоении количества зарегистрированных пользователей или потенциальных клиентов или удвоении любого другого KPI (ключевого показателя эффективности), который мотивировал ваш дизайн-проект.
Как улучшить юзабилити
Существует множество методов изучения юзабилити, но самый простой и полезный — это пользовательское тестирование , которое состоит из 3 компонентов:
- Найдите около репрезентативных пользователей , например клиентов сайта электронной коммерции или сотрудников интрасети (в последнем случае они должны работать за пределами вашего отдела).
- Попросите пользователей выполнить репрезентативных задач с дизайном.
- Понаблюдайте за , что делают пользователи, где они преуспевают и где у них возникают трудности с пользовательским интерфейсом. Заткнись и позволь пользователям говорить.
Важно индивидуально протестировать пользователей и позволить им решать любые проблемы самостоятельно. Если вы поможете им или направите их внимание на какую-либо конкретную часть экрана, вы испортите результаты теста.
Для выявления наиболее важных проблем юзабилити дизайна обычно достаточно тестирования 5 пользователей.Вместо того, чтобы проводить большое и дорогостоящее исследование, лучше использовать ресурсы для запуска множества небольших тестов и пересмотра дизайна между каждым из них, чтобы вы могли исправлять недостатки удобства использования по мере их выявления. Итеративный дизайн — лучший способ повысить качество обслуживания пользователей. Чем больше версий и идей интерфейса вы протестируете с пользователями, тем лучше.
Пользовательское тестирование отличается от фокус-групп, которые являются плохим способом оценки юзабилити дизайна. Фокус-группы имеют место в маркетинговых исследованиях, но для оценки дизайна взаимодействия вы должны внимательно наблюдать за отдельными пользователями, выполняющими задачи с помощью пользовательского интерфейса.Слушать то, что говорят люди, вводит в заблуждение: нужно следить за тем, что они на самом деле делают.
Когда работать над удобством использования
Удобство использования играет роль на каждом этапе процесса проектирования. Возникающая в результате потребность в нескольких исследованиях — одна из причин, по которой я рекомендую делать индивидуальные исследования быстрыми и дешевыми. Вот основные шаги:
- Перед тем, как приступить к разработке новой конструкции, протестируйте старую конструкцию , чтобы определить хорошие части, которые вы должны сохранить или подчеркнуть, и плохие части, которые доставляют пользователям проблемы.
- Если вы не работаете с интрасетью, протестируйте проекты ваших конкурентов , чтобы получить дешевые данные по ряду альтернативных интерфейсов, которые имеют функции, аналогичные вашим собственным. (Если вы работаете в интрасети, прочтите ежегодник по дизайну интрасети, чтобы узнать о других проектах.)
- Проведите полевое исследование , чтобы увидеть, как пользователи ведут себя в естественной среде обитания.
- Сделайте бумажных прототипов одной или нескольких новых дизайнерских идей и протестируйте их. Чем меньше времени вы потратите на эти дизайнерские идеи, тем лучше, потому что вам нужно будет изменить их все на основе результатов тестирования.
- Уточните идеи дизайна, которые лучше всего проверяют через нескольких итераций , постепенно переходя от прототипирования с низкой точностью к представлениям с высокой точностью, которые выполняются на компьютере. Проверяйте каждую итерацию.
- Проверьте дизайн на соответствие установленным руководствам по удобству использования , будь то ваши собственные исследования или опубликованные исследования.
- После того, как вы примете решение и внедрите окончательный проект , протестируйте его снова. Во время реализации всегда возникают небольшие проблемы с удобством использования.


Не откладывайте пользовательское тестирование до тех пор, пока не получите полностью реализованный дизайн. Если вы это сделаете, будет невозможно исправить подавляющее большинство критических проблем юзабилити, которые обнаруживает тест. Многие из этих проблем, вероятно, будут структурными, и их решение потребует серьезной перестройки архитектуры.
Единственный способ обеспечить высокое качество взаимодействия с пользователем — это начинать пользовательское тестирование на ранней стадии процесса проектирования и продолжать тестирование на каждом этапе.
Где тестировать
Если вы проводите хотя бы одно исследование пользователей в неделю, стоит создать специальную лабораторию юзабилити. Однако для большинства компаний нормально проводить тесты в конференц-зале или офисе — при условии, что вы можете закрыть дверь, чтобы вас не отвлекали. Важно то, что вы получаете реальных пользователей и сидите с ними, пока они используют дизайн. Блокнот — единственное, что вам нужно.
Однако для большинства компаний нормально проводить тесты в конференц-зале или офисе — при условии, что вы можете закрыть дверь, чтобы вас не отвлекали. Важно то, что вы получаете реальных пользователей и сидите с ними, пока они используют дизайн. Блокнот — единственное, что вам нужно.
RSpak NN-G — ShodexHPLC.com
Скрытый ярлык
Избранные столбцы
Скрытый ярлык
U.Список столбцов S. Pharmacopeia (USP)
Скрытый ярлык
HILIC — на полимерной основе
Скрытый ярлык
Обращенная фаза — на полимерной основе
Скрытый ярлык
Обмен лигандов, исключение ионов и специализированный GFC
Скрытый ярлык
Эксклюзионная хроматография
Скрытый ярлык
Ионообменная хроматография
Скрытый ярлык
Хроматография гидрофобного взаимодействия
Скрытый ярлык
Эксклюзивное использование и специальность
Скрытый ярлык
Аффинная хроматография и хиральное разделение
Скрытый ярлык
Колонка Коммутация
Скрытый ярлык
ЖХ / МС и экспресс-анализ
Скрытый ярлык
Ионная хроматография
Скрытый ярлык
Обращенная и нормальная фаза — на основе кремнезема
Скрытый ярлык
Очистка GPC
Скрытый ярлык
Пункты поэтапного отказа на 2018-2021 годы
Скрытый ярлык
Колонки для ионообменной хроматографии для УВЭЖХ
.